


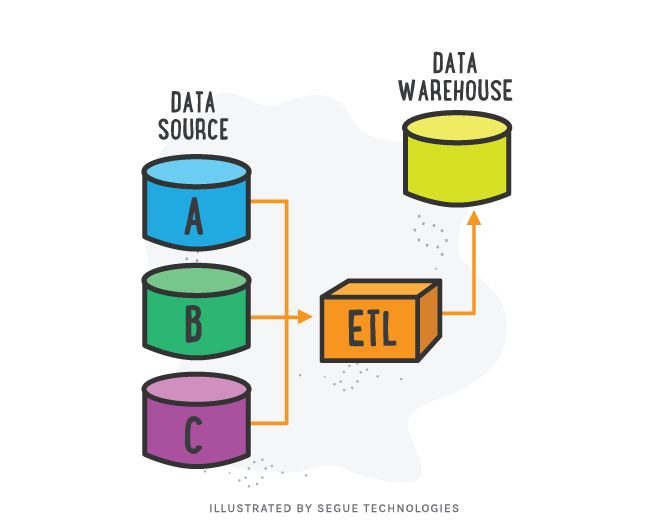
Big organizations implement enterprise Data Warehouses for reporting purposes and data analysis. These Online Analytical Processing (OLAP) reporting databases help in simplifying the decision making process for businesses. The data for the Data Warehouses is brought over from Online Transactional Processing (OLTP) Production systems. Extract, Transformation and Loading (ETL) is the process of moving data from multiple OLTP sources and then transforming it and finally loading it into a Data Warehouse. This ETL process is usually a recurring process occurring daily, weekly, etc. and should be maintained and updated accordingly. The Data Warehouse is then used by external sources like Reporting Services to generate complex business insights and solutions.
Extraction
The Extract process is the first step of the ETL process. It brings together multiple sources like legacy source systems, OLTP databases, flat files, etc. These diverse data sources are brought together in a logical way and their relationship needs to be clearly defined to integrate data. The source data needs to be identified and cleaned while keeping the target destination in mind. The logical mapping of the data is a critical aspect of this step and should highlight the transformation. It is important to analyze the data for retrieval. Null values are critical when considering joins. When used as foreign keys they will cause data loss. Outer joins are a must to handle such cases in relational databases. DATE fields are equally important due to the various formats they can be stored in. It is important to identify the different formats and store them consistently.
It is also necessary to identify any changes to the initial version of the data and to store this copy. This can be used to capture changed data and, in the next iteration, this version can be used to compare to use the delta to move forward.
Transformation
The Transformation helps massage data to adhere to business requirements and cleans it to improve the quality. This is performed in the staging area, where data is transformed to satisfy the business rules and logical data checks. The quality of data should be checked after the extraction, and then again after the cleaning and confirming. The count (*) can be used to check the record numbers. Rules should be enforced on column properties. For example, null values should be used accordingly, ranges for numeric values should be established and length of columns should adhere to a valid minimum and maximum limit. At times, a window of the data is selected to move forward, for example, only certain number of fields and number of records limited by added filters are used. In some cases, transcoding or encoding of data brings consistency among different sources, for example , converting “Male” or “1” to “M”. Mathematically deriving values, for example, total_amount = quantity * unit_amount. These are just a few ways in which the data can be transformed.
Loading
Loading is the process of moving the data to an OLAP Data Warehouse type of destination. It can be divided into two sub-stages: the initial load and the incremental update. The initial load contains all the data before the start and the incremental load is the updating of the initial load periodically. In the loading process, dimensions are loaded before facts. While loading dimensions, the primary key should be a unique, mostly sequential integer called the Surrogate Key. The tables need to be de-normalized and all attributes of the dimension need to take a single value for each primary key. Fact tables contain measurements of the business process. While building the fact table, the final step is to convert the natural keys in the new input records into correct, contemporary surrogate keys. ETL maintains a special surrogate key lookup table for each dimension. This table is updated whenever a new dimension entity is created, or when an existing dimension is updated.
There are a few things to consider with respect to performance while loading the data. Indexes can bring down performance of the load process. It is advised to drop the indexes during the load process and recreate them afterwards. Also, segregation of the updates from the inserts is advised. Table and index partitions can be used to improve performance. One of the best partition strategies on fact tables is to partition by using the date key. Because the date dimension is preloaded and static, you know what the surrogate keys are. Also, the redo log or the rollback log, which are essential in an OLTP environment, can be a hindrance in the OLAP setup. Here data is almost always loaded and dealt with in bulk and, in case of data loss, can be reloaded easily.
The Extract, Transform, and Loading process is an integral part of moving data from different source systems to Data Warehouse environments. These Data Warehouses produce reports and insight to organizations helping the decision making process. Proper planning and careful execution is required during this process. Isolating ETL into the Extract, Transform, and Loading stages helps to better understand the process, helping in the scalability and making it easy to maintain and update.